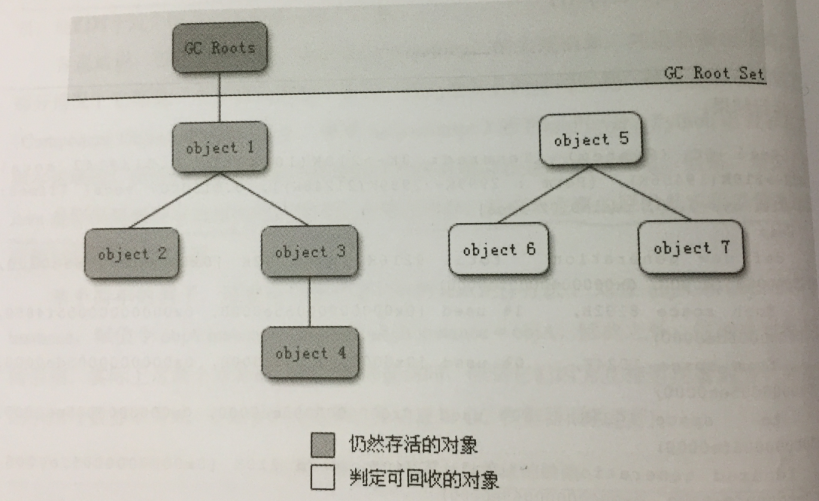
在《JVM中判断对象是否存活的方法》这篇博文中,我们了解了主流的Java虚拟机都是通过可达性分析算法判断对象是否存活的。其实,即使在可达性分析算法中被判断为不可达的对象,也并非是“非死不可”的,它们此时处于“缓刑”阶段,要真正宣告一个对象的死亡,至少要经历两次标记过程:如果对象在可达性分析算法中被判断为不可达,即不存在任何GC Roots到这个对象的引用链,那么这个对象会被第一次标记,并进行一次筛选,筛选条件是“这个对象是否有必要执行finalize()方法”。若对象没有覆盖finalize()方法,或者该对象的finalize()方法已经被JVM调用过,这两种情况都被视为“没有必要执行”,没有必要执行finalize()方法的对象将被第二次标记,随后便被回收。如果此对象被判定为有必要执行finalize()方法,那么这个对象将被放置在一个叫做F-Queue的队列中,这个队列将被一个由JVM自动建立,低优先级的Finalizer线程去执行。这里的“执行”只意味着JVM会触发对象的finalize()方法,但不承诺会等待它运行结束,因为如果一个对象在finalize()中执行缓慢,或者发生了死循环,这将可能导致F-Queue队列中其他对象永久处于等待,甚至导致整个内存回收系统崩溃。finalize()方法是对象逃脱死亡命运的最后一次机会,稍后GC将对F-Queue中的对象进行第二次标记,如果对象要在finalize()方法中拯救自己,那么它只要重新与引用链上的任意一个对象建立关联即可,譬如通过this关键字把自己赋值给某个类变量或者对象的成员变量,那么在第二次标记时它将被移除出“即将回收”的集合;如果到这个时候对象还没逃脱死亡的命运,它将被第二次标记,那么基本上它就真的可以被回收了。这个过程可以通过下面的流程图来表示: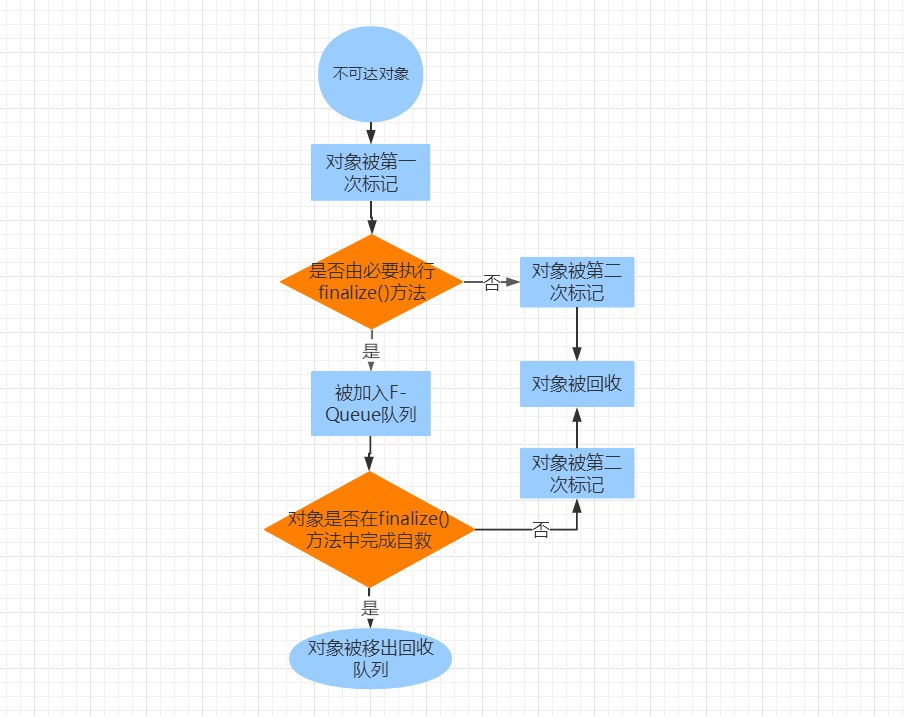
此外,我们可以通过下面的程序看到,一个对象的finalize()方法被执行,但是它仍然可以存活:
public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, i am still alive :)");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize mehtod executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
public static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinalizeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
// 因为Finalizer方法优先级很低,暂停0.5秒,以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
// 下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
// 因为Finalizer方法优先级很低,暂停0.5秒,以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
}
}
运行程序:
finalize mehtod executed!
yes, i am still alive :)
no, i am dead :(
从输出结果的第一、二行我们可以知道,SAVE_HOOK曾引用的对象,其finalize()方法的确被GC触发过,但是它在finalize()中成功拯救了自己,得以不被回收。但是在第三行中,程序中的一段与之前一模一样的代码,执行结果却是“no, i am dead :(”,这是因为任何一个对象的finalize()方法只会被系统自动调用一次。如果对象面临下一次回收,它的finalize()方法不会再被执行。
从上面的程序中,我们再次体会到了,finalize()方法的局限性,它不同于C/C++中的析构函数,它的运行代价高昂,不确定性大,无法保证各个对象的调用顺序,所以建议大家完全可以忘掉Java语言中这个方法的存在,这在《finalize()方法的使用》中我们已经介绍过。