在SpringMVC中,我们可以通过使用@ModelAttribute注解标记方法,实现类似于Struts2中Preparable拦截器的效果,其使用方法我们已经在《SpringMVC中如何处理模型数据》中讲述过了。
现在我们仍以上篇文章中的更新操作为例,来讨论@ModelAttribute的工作过程。即:有一个User类,有id、userName、email三个属性。现在要完成一个更新操作,但是其中有一项属性不能被修改,例如id,那么只能修改两项属性,userName和email,所以从form表单传递的信息就只能有这两项,我们是通过@ModelAttribute注解标记方法来实现的:(其中数据库相关的操作仅采用模拟的方式)
index.jsp:
controller:
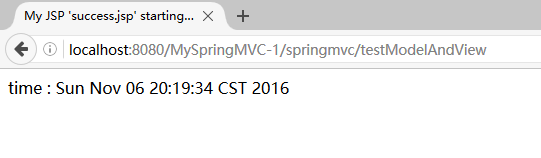
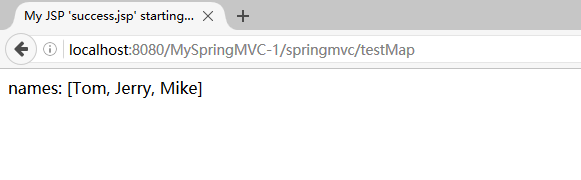
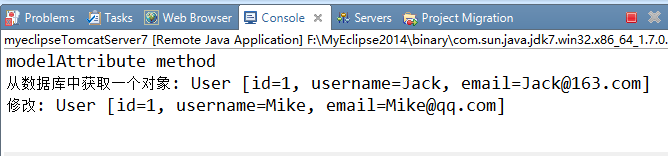
运行后,在控制台输出:
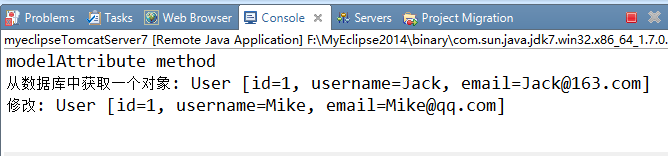
在这个例子中,SpringMVC通过映射请求调用目标处理方法testModelAttribute方法之前,做了下面三件事情:
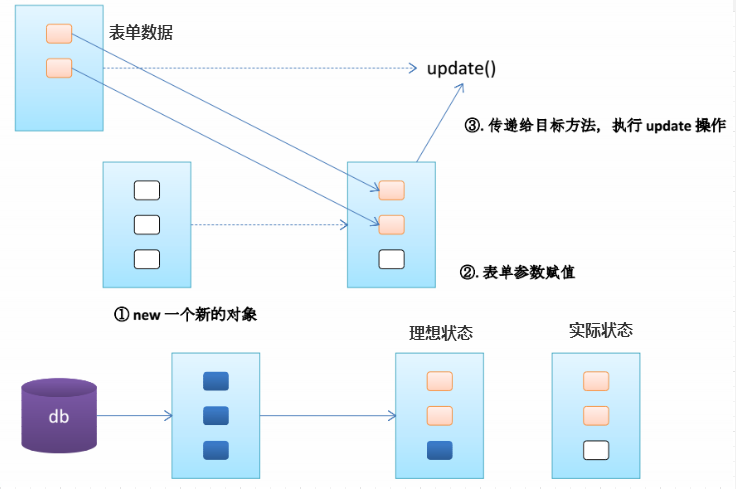
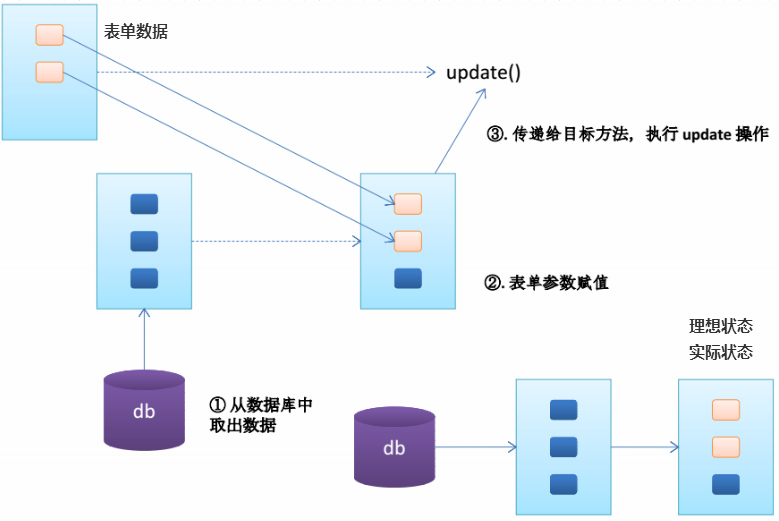
第1步: 执行 @ModelAttribute 注解修饰的方法: 从数据库中取出对象,把对象放入到了 Map 中,键为:user。
第2步: SpringMVC 从 Map 中取出 User 对象 user, 并把表单的请求参数赋给 user 的对应属性。
第3步: SpringMVC 把上述对象作为参数传入目标方法testModelAttribute(User user)。
通过阅读SpringMVC的源码,我了解了这三个步骤具体是这样实现的:
第1步: 执行 @ModelAttribute 注解修饰的方法,实际上把 @ModelAttribute 方法中 Map 中的数据user放在了 implicitModel(这是一个BindingAwareModelMap类型的对象,BindingAwareModelMap类型实现了Map接口) 中。
第2步:核心的功能都在第2步实现,这一步主要做了三件事,其中核心步骤是前两件事,即 2.1 和 2.2 :
2.1(第一件事):确定查找键值对所需要的键(key):
2.1.1:若目标方法的 POJO 类型的参数没有使用 @ModelAttribute 作为修饰, 则 key 为 POJO 类名第一个字母的小写;
2.1.2:若目标方法的 POJO 类型的参数使用了@ModelAttribute 来修饰, 则 key 为 @ModelAttribute 注解的 value 属性值。
在上面的例子中,目标方法testModelAttribute(User user)中的入参没有被@ModelAttribute修饰,所以key值为POJO 类名第一个字母的小写形式,即“user”。
2.2(第二件事):在 implicitModel(即map) 中查找 key 对应的对象:
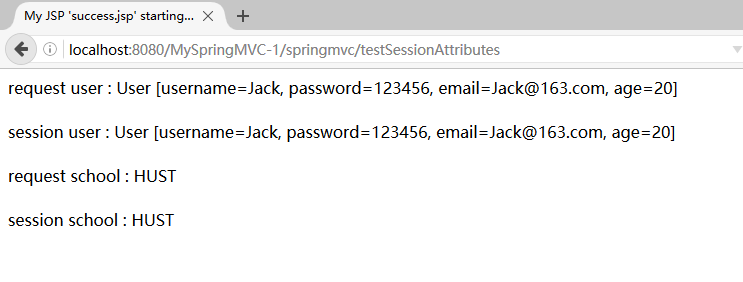
2.2.1:若 @ModelAttribute 标记的方法在 Map 中保存过这样一个键值对, 其 key 和 2.1 确定的 key 一致, 则会获取到key对应的键值对的value值;
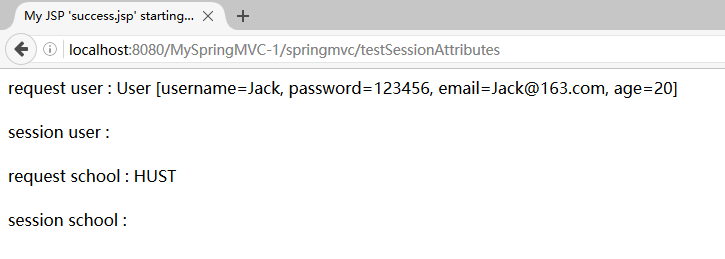
2.2.2:若 implicitModel 中不存在 key 对应的对象,则检查当前的控制器类是否被@SessionAttributes注解修饰,如果使用了@SessionAttributes注解修饰,且@SessionAttributes注解的value值中包含了key,则尝试从HttpSession中获取key所对应的value值,如果value值存在则获取到,如果value值不存在则抛出异常。
2.2.3:如果没有使用@SessionAttributes注解修饰该控制器类,或者使用了,但是@SessionAttributes注解中的value值不包含key,则SpringMVC会通过反射来创建一个POJO类型的对象。
2.3(第三件事):,用表单中传递过来的参数值去更新2.2确定的value值(或通过反射建立的对象)。
第3步:同上面的第3步描述的一样,即SpringMVC 把上述对象作为参数传入目标方法。
以上就是@ModelAttribute注解的工作流程,我们了解了流程之后,就会发现,在2.2.2中有这样一种情况:如果:
①在 implicitModel 中不存在 key 对应的对象;
②控制器类有标记了@SessionAttributes注解;
③@SessionAttributes注解的value值中包含key;
④HttpSession域中不存在该key值对应的value值。
当同时满足这4种情况时,就会抛出异常,解决方法有两种:
1、通过@ModelAttribute注解修饰目标方法的入参,确定一个key值,使其不被包含在@SessionAttributes注解的value值中。
2、使用@ModelAttribute方法,在目标方法调用之前,将key对应的键值对放入implicitModel 中。