Hibernate配置文件主要用于配置数据库连接和Hibernate运行时所需的各种属性。
每个Hibernate配置文件对应一个Configuration对象。
Hibernate配置文件可以有以下两种形式:
1. hibernate.properties
2. hibernate.cfg.xml (常用形式)
hibernate.cfg.xml的常用属性
JDBC连接属性
- connection.username:数据库用户名。
- connection.password:数据库用户密码。
- connection.driver_class:数据库JDBC驱动。
- connection.url:数据库URL。
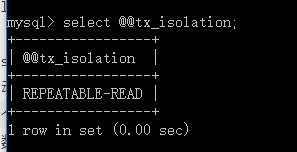
- dialect:配置数据库的方言,根据底层的数据库不同产生不同的sql语句,Hibernate 会针对数据库的特性在访问时进行优化。
C3P0数据库连接池属性
- hibernate.c3p0.max_size:数据库连接池的最大连接数。
- hibernate.c3p0.min_size:数据库连接池的最小连接数。
- hibernate.c3p0.timeout:数据库连接池中连接对象在多长时间没有使用过后,就应该被销毁。
- hibernate.c3p0.idle_test_period:表示连接池检测线程多长时间检测一次池内的所有连接对象是否超时。连接本身不会把自己从连接池中移除,而是专门有一个线程按照一定的时间间隔来做这件事,这个线程通过比较连接对象最后一次被使用时间和当前时间的时间差来和timeout做对比,进而决定是否销毁这个连接对象。
- hibernate.c3p0.acquire_increment:当数据库连接池中的连接耗尽时, 每一次获取多少个数据库连接。
- hibernate.c3p0.max_statements:缓存 Statement 对象的数量。
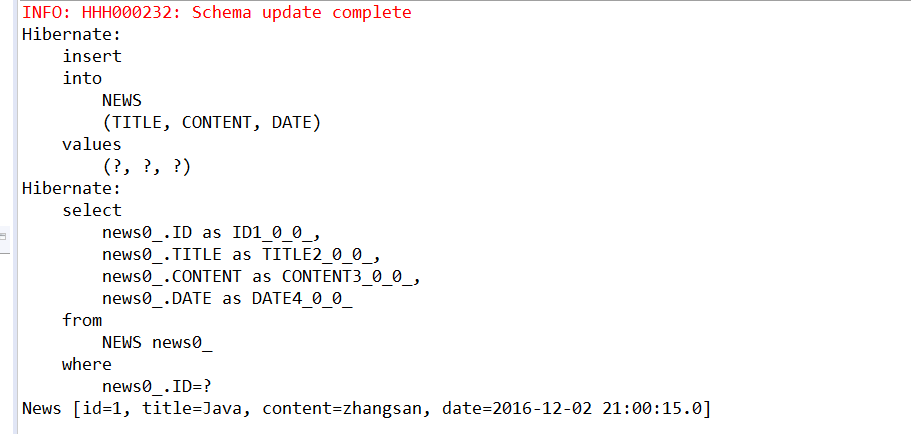
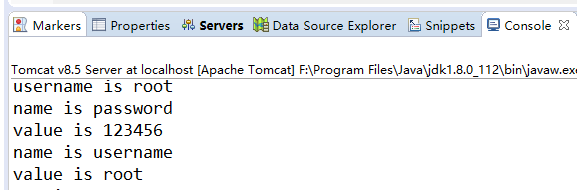
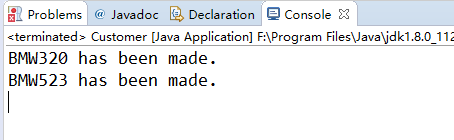
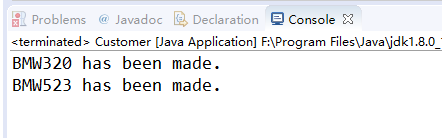
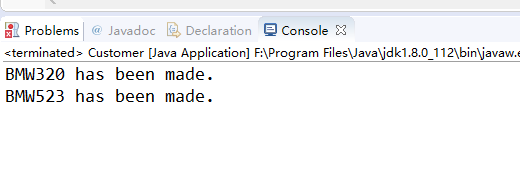
下面我们配置C3P0数据源,然后调用session.doWork方法查看获取的连接是否来自于C3P0:
首先导入jar包: 123456789<!-- 配置 C3P0 数据源 --><property name="hibernate.c3p0.max_size">10</property><property name="hibernate.c3p0.min_size">5</property><property name="c3p0.acquire_increment">2</property><property name="c3p0.idle_test_period">2000</property><property name="c3p0.timeout">2000</property><property name="c3p0.max_statements">10</property>
123456789<!-- 配置 C3P0 数据源 --><property name="hibernate.c3p0.max_size">10</property><property name="hibernate.c3p0.min_size">5</property><property name="c3p0.acquire_increment">2</property><property name="c3p0.idle_test_period">2000</property><property name="c3p0.timeout">2000</property><property name="c3p0.max_statements">10</property>
|
|
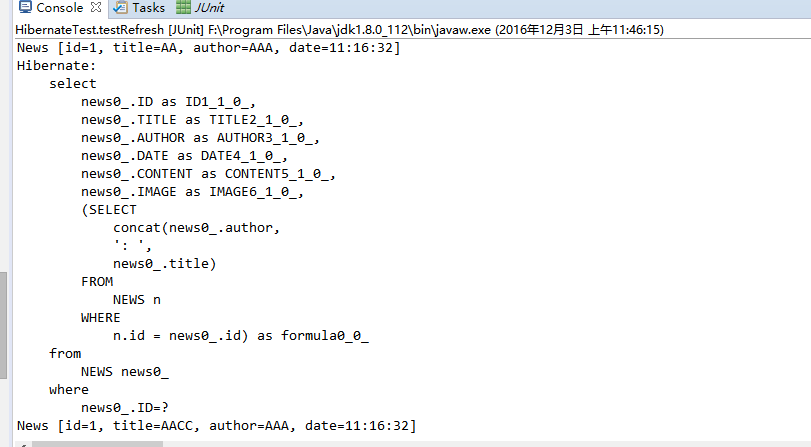
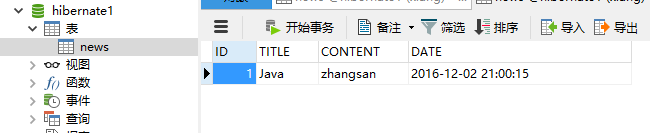
运行结果: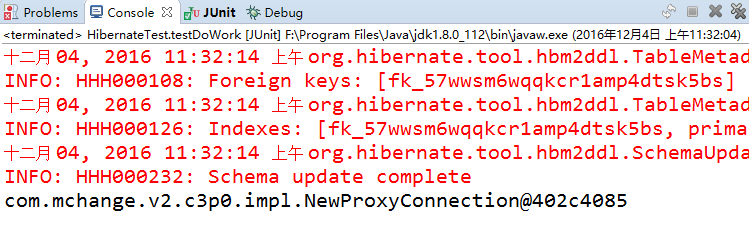
其他属性
- show_sql:是否将运行期生成的SQL输出到日志以供调试,取值为 true | false。
- format_sql:是否将SQL语句转化为格式良好的SQL语句,取值 true | false。
- hbm2ddl.auto:在启动和停止时自动地创建,更新或删除数据库模式,取值 create | update | create-drop | validate。
- hibernate.jdbc.fetch_size:实质是调用Statement.setFetchSize()方法设定JDBC的Statement读取数据的时候每次从数据库中取出的记录条数。
例如一次查询1万条记录,对于Oracle的JDBC驱动来说,是不会一次性把1万条取出来的,而只会取出fetchSize条记录,当结果集遍历完了这些记录以后,再去数据库取fetchSize条数据,因此大大节省了无谓的内存消耗。fetch Size设的越大,读数据库的次数越少,速度越快,但是对web服务器资源的消耗越严重;fetchSize越小,读数据库的次数越多,速度越慢,但是对web服务器资源的消耗越小。Oracle数据库的JDBC驱动默认的fetchSize=10,是一个保守的设定,根据测试,当Fetch Size=50时,性能会提升1倍之多,当 fetchSize=100,性能还能继续提升20%,fetchSize继续增大,性能提升的就不显著了。
但是并不是所有的数据库都支持Fetch Size特性,例如MySQL就不支持。 - hibernate.jdbc.batch_size:设定对数据库进行批量删除,批量更新和批量插入的时候的批次大小,类似于设置缓冲区大小的意思。batchSize 越大,批量操作时向数据库发送sql的次数越少,速度就越快。测试结果是当batchSize=0的时候,使用Hibernate对Oracle数据库删除1万条记录需要25秒,batchSize = 50的时候,删除仅仅需要5秒!Oracle数据库 batchSize=30 的时候比较合适。