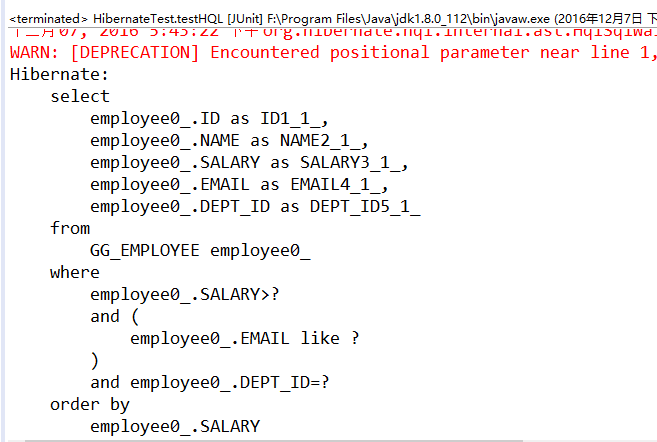
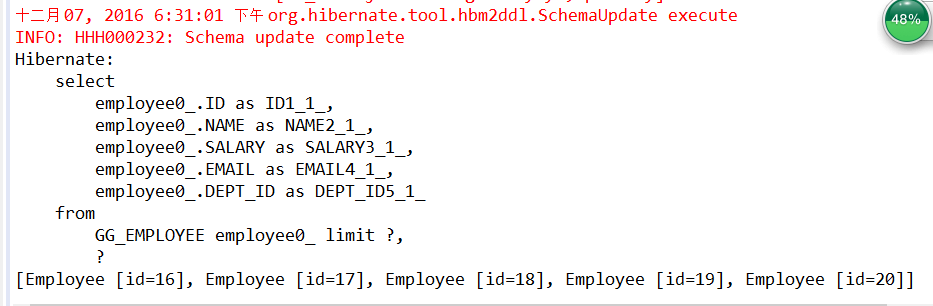
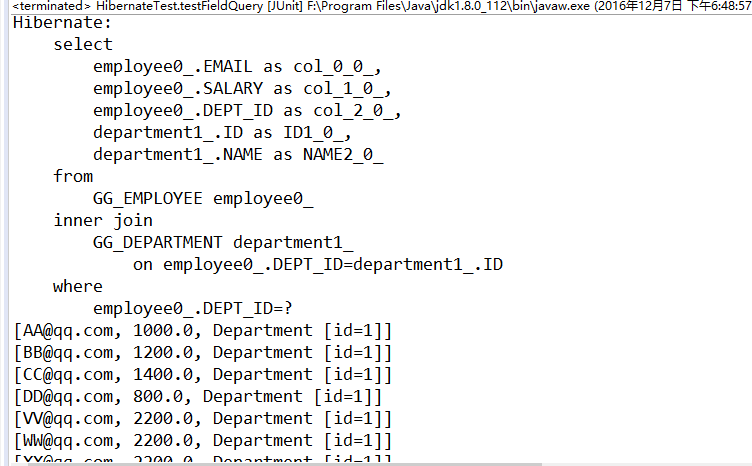
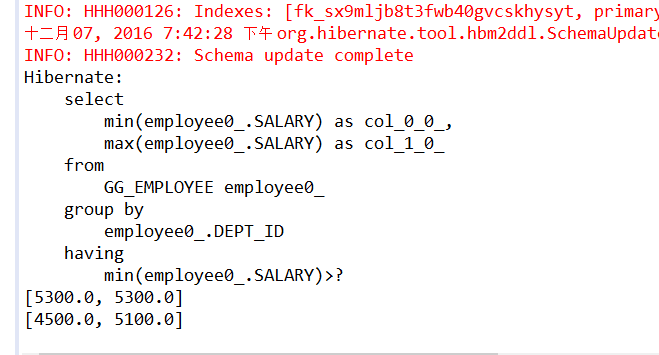
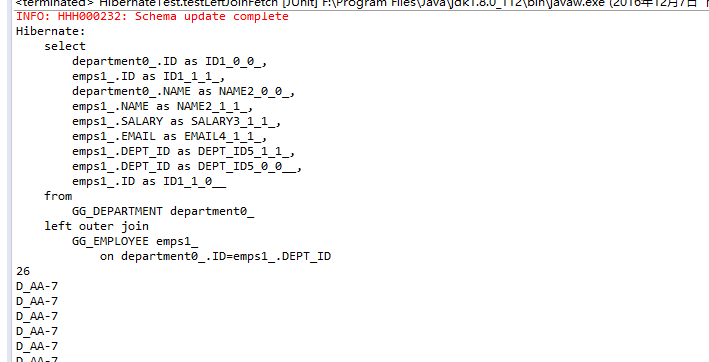
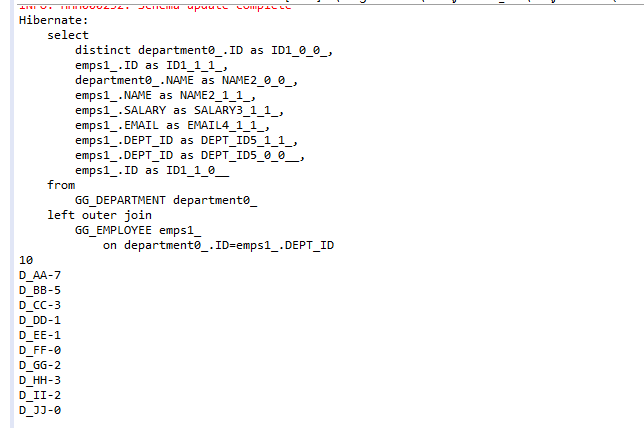
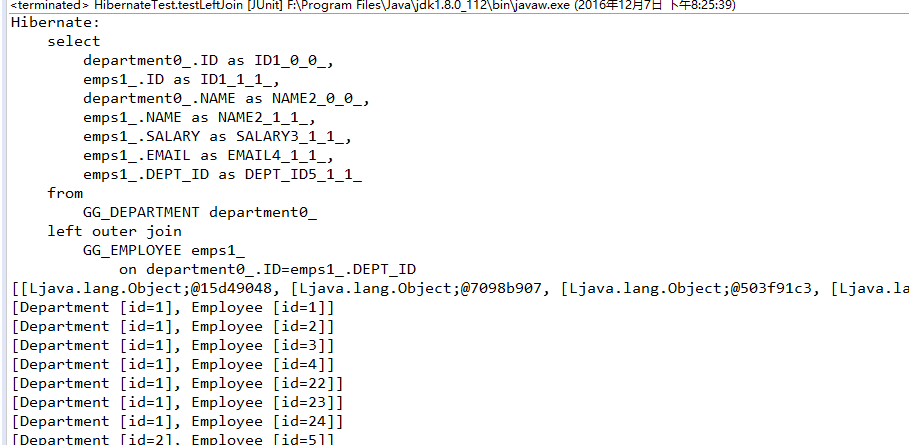
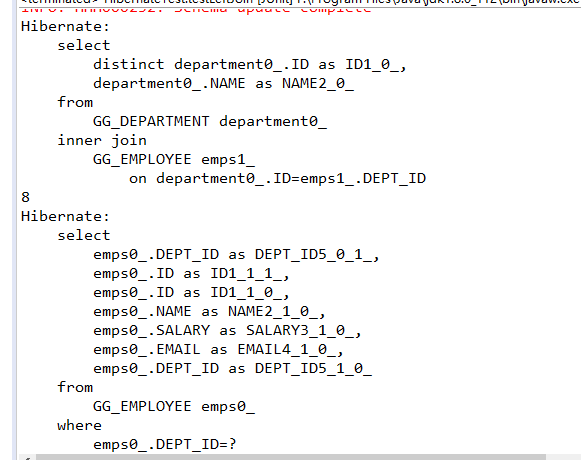
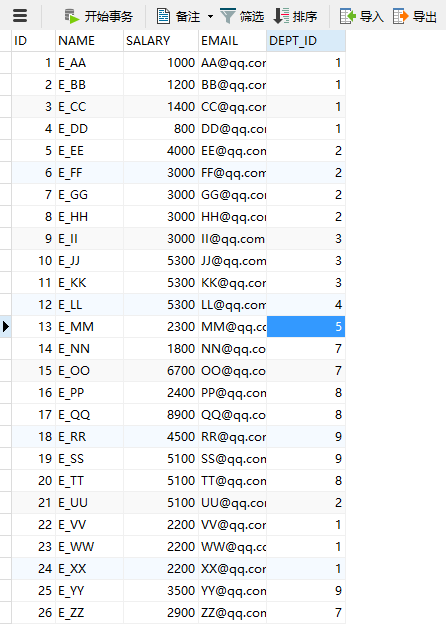
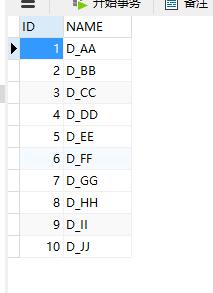
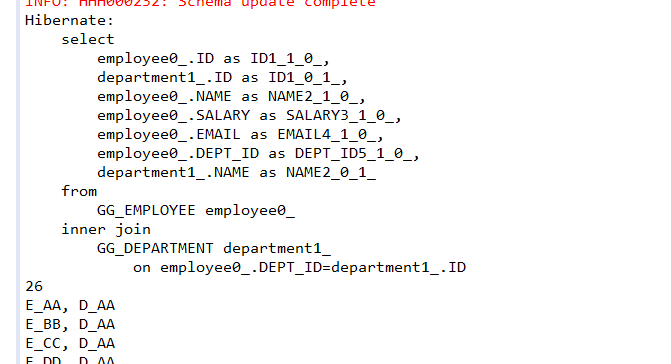
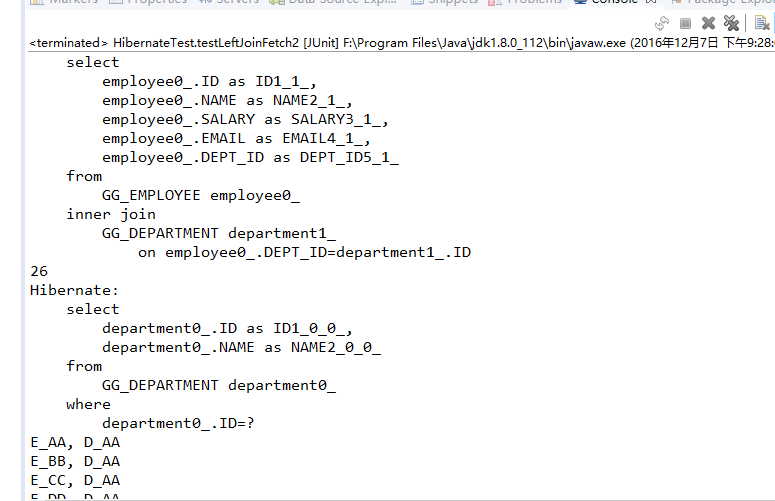
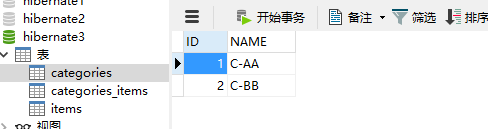
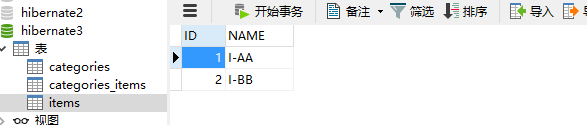
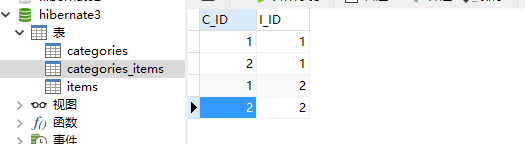
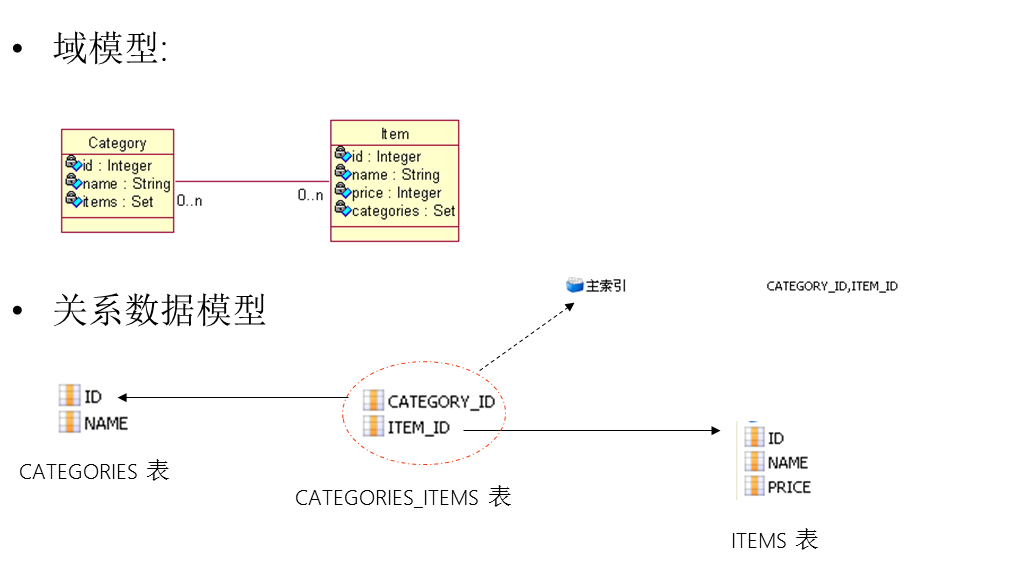
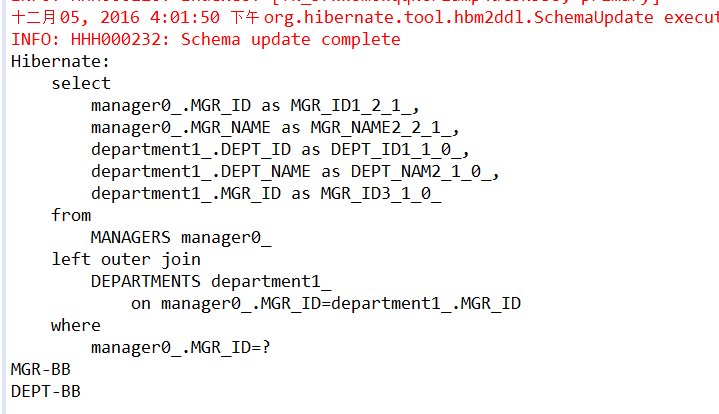
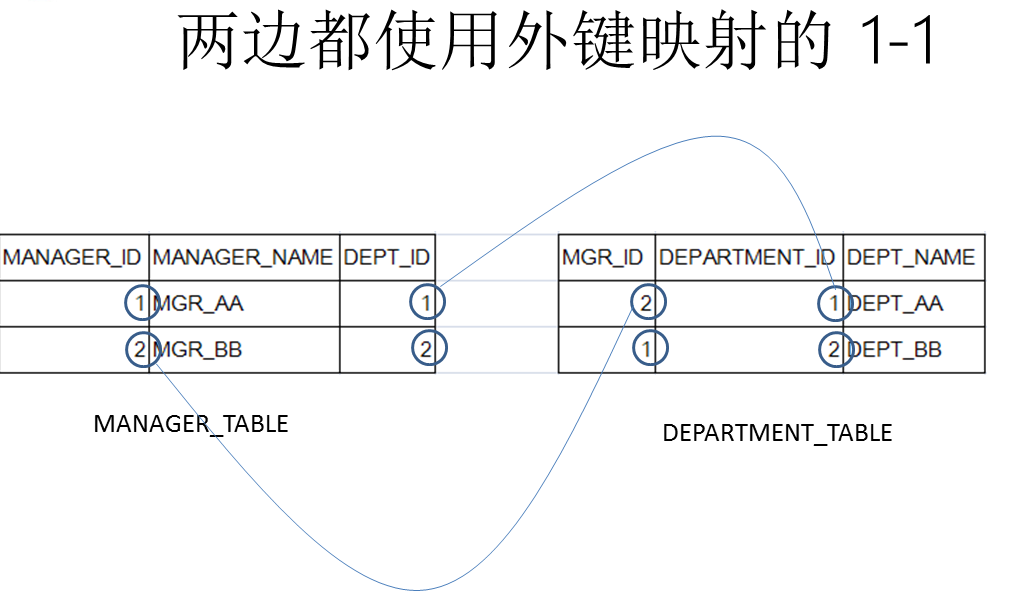
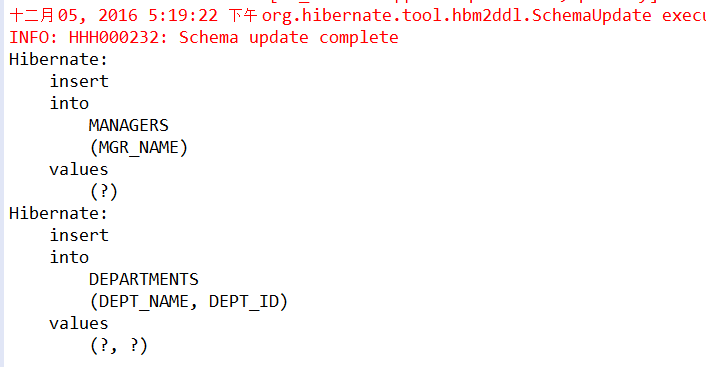
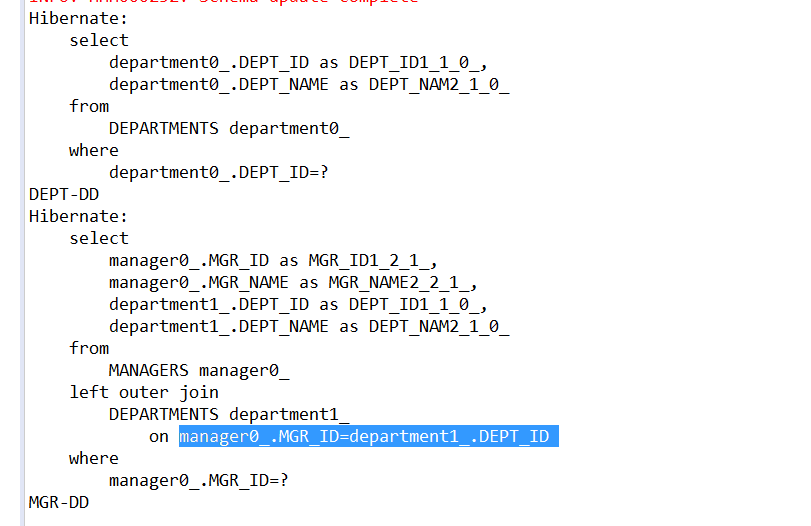
Hibernate提供本地SQL查询来完善HQL不能涵盖所有的查询特性。例如,可以通过下面的程序完成插入操作:123456789 public void testNativeSQL(){ String sql = "INSERT INTO gg_department VALUES(?, ?)"; Query query = session.createSQLQuery(sql); query.setInteger(0, 1) .setString(1, "ATGUIGU") .executeUpdate(); }
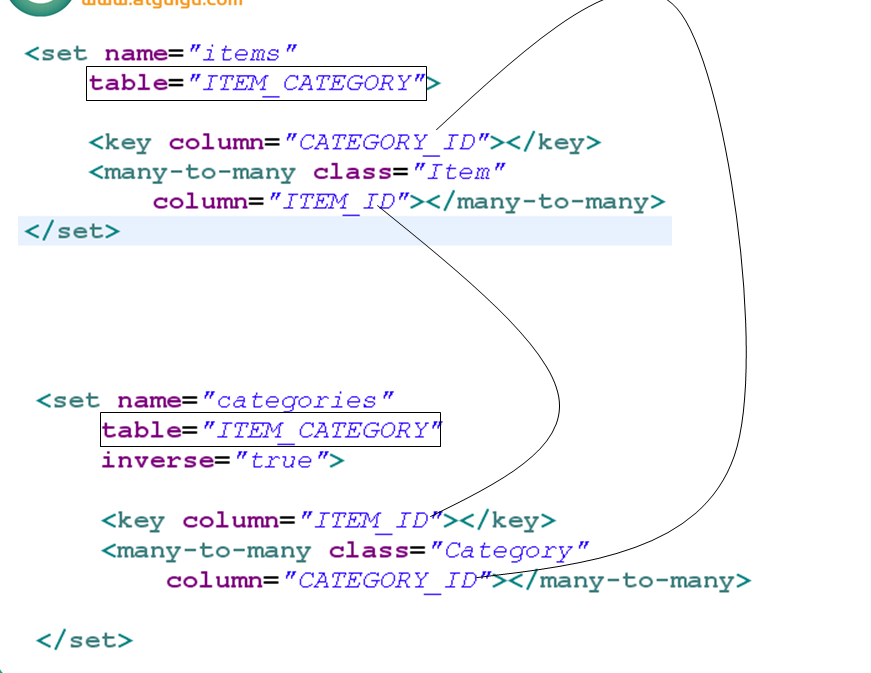
注意,本地SQL语句中,gg_department是表名,而不是HQL语句中的类名。
其实,HQL也支持删除和更新的操作(不支持插入操作),例如,下面的例子演示了用HQL进行删除:1234567 public void testHQLUpdate(){ String hql = "DELETE FROM Department d WHERE d.id = :id"; session.createQuery(hql).setInteger("id", 1) .executeUpdate(); }