Hibernate检索对象的方式
Hibernate提供了以下集中检索对象的方式:
- 导航对象图检索方式:即根据已经加载的对象导航到其他对象。
- OID检索方式:按照对象的OID来检索对象。
- HQL检索方式:使用面向对象的HQL查询语言。
- QBC检索方式:使用QBC(Query By Criteria)。 API来检索对象,这种API封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口。
- 本地SQL检索方式:使用本地数据库的SQL查询语句。
HQL检索方式
本文主要介绍HQL检索方式。
HQL(Hibernate Query Language)是面向对象的查询语言,它和SQL查询语言有些相似。在Hibernate提供的各种检索方式中,HQL是使用最广的一种检索方式。它有如下功能:
在查询语句中设定各种查询条件;
支持投影查询;
支持分页查询;
支持连接查询
支持分组查询,允许使用HAVING和GROUP BY关键字;
提供内置聚集函数,如sum(),min()和max();
支持子查询;
支持动态绑定参数;
能够调用用户定义的SQL函数或标准的SQL函数。
HQL检索方式包括以下步骤:
1.通过Session的createQuery()方法创建一个Query对象,它包括一个HQL查询语句,HQL语句中可以包含命名参数;
2.动态绑定参数;
3.调用Query相关方法执行查询语句。
Query接口支持方法链编程风格,它的setXxx()方法返回自身实例,而不是void类型。
HQL VS SQL:
HQL查询语句是面向对象的,Hibernate负责解析HQL查询语句,然后根据对象-关系映射文件中的映射信息,把HQL查询语句翻译成相应的SQL语句。HQL查询语句中的主体时域模型中的类及类的属性。
SQL查询语句是与关系数据库绑定在一起的。SQL查询语句中的主体时数据库表及表的字段。
绑定参数:
Hibernate的参数绑定机制依赖于JDBC API中的PreparedStatement的预定义SQL语句功能。
HQL的参数绑定有两种形式:
1.按参数名绑定:在HQL查询语句中定义命名参数,命名参数以”:”开头;
2.按参数位置绑定:在HQL查询语句中用”?”来定义参数位置。
Hibernate可以通过setEntity()方法把参数与一个实体对象绑定,还可以通过setParameter()方法来绑定任意类型的参数。
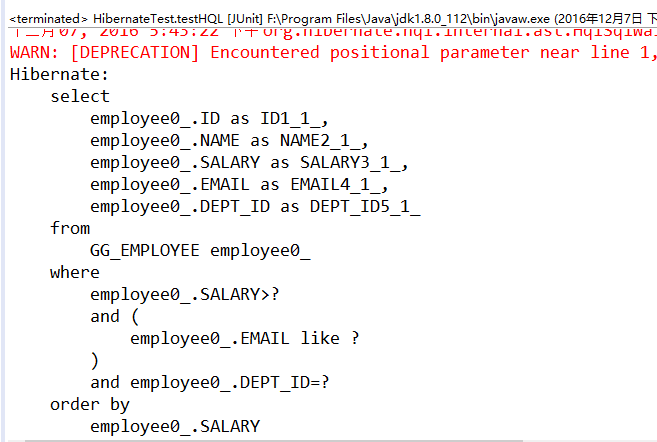
例如,可以通过下面的代码使用基于位置的参数来查询employee表中salary>1000,email字段中包含字符A,且属于部门号为1的部门的记录,查询结果按照salary进行排序:
在控制台打印的sql语句为:
或者使用基于参数名的参数实现相同的功能:
HQL分页查询
HQL主要通过下面两个方法来实现分页查询:
setFirstResult(int firstResult):设定从哪一个对象开始检索,参数firstResult指定这个对象在查询结果中的索引位置。索引位置的起始值为0,默认情况下,Query从查询结果中的第一个对象开始检索。
setMaxResults(int maxResults):设定一次最多检索出的对象的数目。默认情况下,Query和Criteria接口检索出查询结果中的所有的对象。
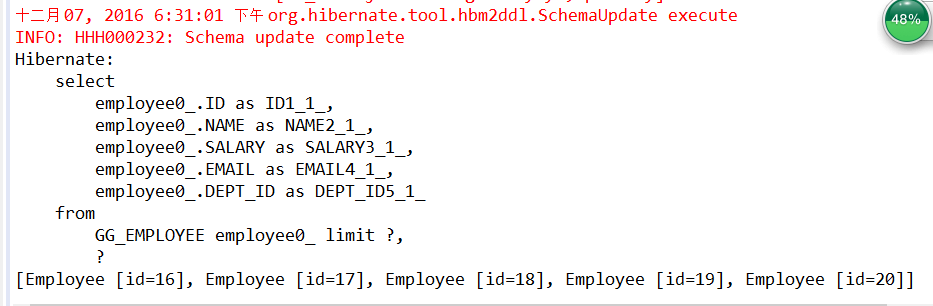
下面的代码实现了将每5条记录分为一页,查询第4页的记录的功能:
HQL命名查询
可以在映射文件中定义命名查询语句,实现将HQL语句的外置化,以实现通过不修改源码达到修改功能的效果。下面进行演示:
在Employee.hbm.xml文件中定义命名查询语句,其中query节点和class节点并列:
通过session.getNamedQuery()方法查询,参数为上述query节点的name属性值:
HQL投影查询
投影查询,即希望查询的结果仅包含实体的部分属性。通过SELECT关键字实现。下面的代码只希望查询指定部门员工的email,salary和dept属性。
这时候,返回的list中的元素是Object数组,其中每一个Object数组中存放了一条记录对应的属性值。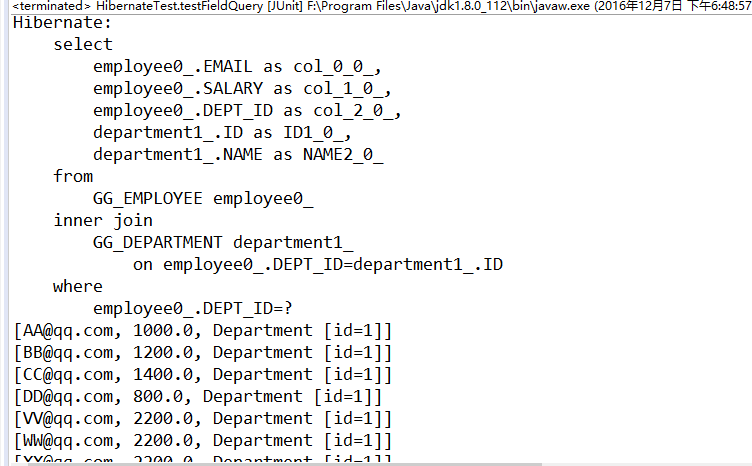
遍历元素为Object数组的list有点麻烦,可以通过另一种方式将查询的属性值存放在一个Employee对象中:先在Employee类中定义一个包含指定属性的构造器,然后通过下面的程序可以查询对应的属性:
Employee.java
|
|
注意构造器中属性顺序需和HQL语句中的属性顺序一致。
HQL报表查询
报表查询用于对数据分组和统计,与SQL一样,HQL利用GROUP BY关键字对数据分组,用HAVING关键字对分组数据设定约束条件。
在HQL查询语句中可以调用以下聚集函数:
count()
min()
max()
sum()
avg()
下面的代码演示了报表查询,根据department对employee进行分组,然后查询部门内最低工资大于3000的部门的最低工资和最高工资。
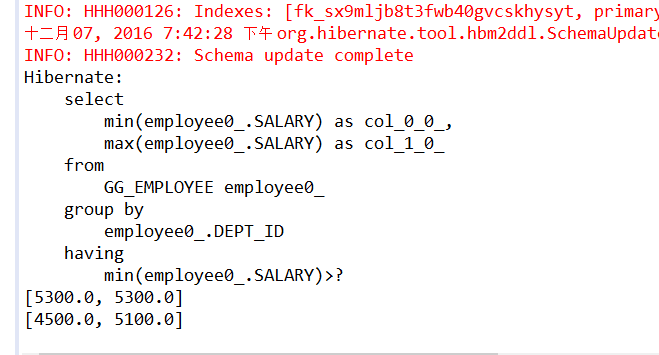
HQL(迫切)左外连接
迫切左外连接:
在HQL中通过LEFT JOIN FETCH关键字表示迫切左外连接检索策略。
list()方法返回的集合存放实体对象的引用,每个Department对象关联的Employee集合都被初始化,存放所有关联的Employee的实体对象。
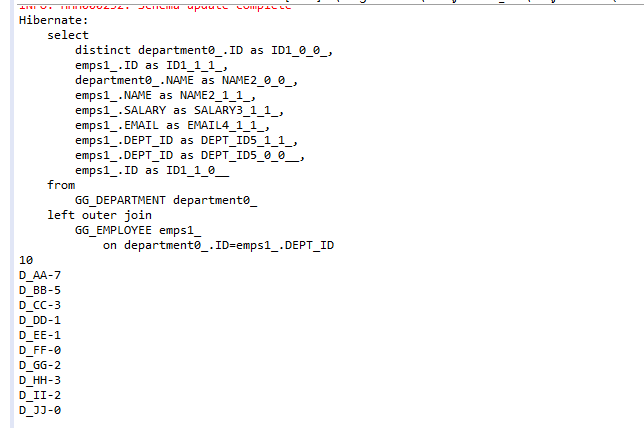
查询结果中可能会包含重复元素,可以通过一个HashSet来过滤重复元素,也可以在HQL语句中使用DISTINCT关键字来过滤。
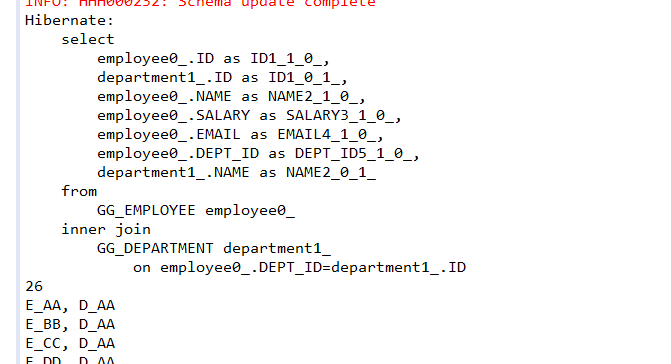
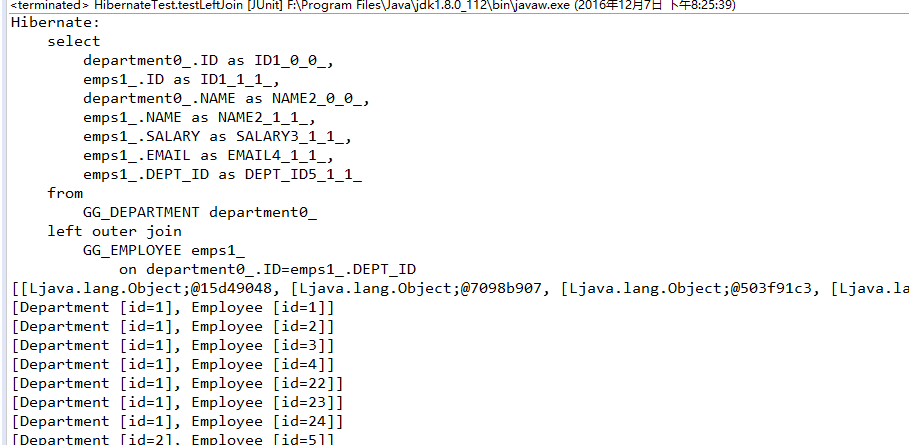
下面的例子测试了迫切左外连接:
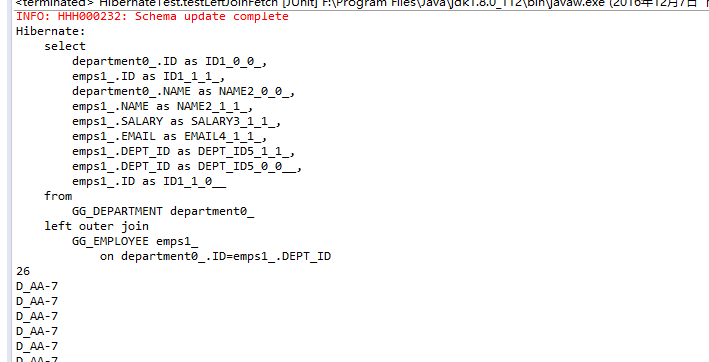
这种情况下将查询出所有的26条记录(包含重复的department),如果将注释行打开,或者将hql改为”SELECT DISTINCT d FROM Department d LEFT JOIN FETCH d.emps”,可以过滤掉重复元素:
左外连接:
HQL使用LEFT JOIN关键字表示左外连接查询。
list()方法返回的集合中存放的是对象数组类型。(存放了一个Department对象和一个Employee对象)。
由于list()方法返回的集合中存放的是一个Department对象和一个Employee对象构成的对象数组,所以不能用hashset来去重,因为每一个对象数组其实是不一样的。
如果需要去重,可以通过SELECT关键字使list()方法返回的集合中仅包含Department对象,然后用DISTINCT来去重。
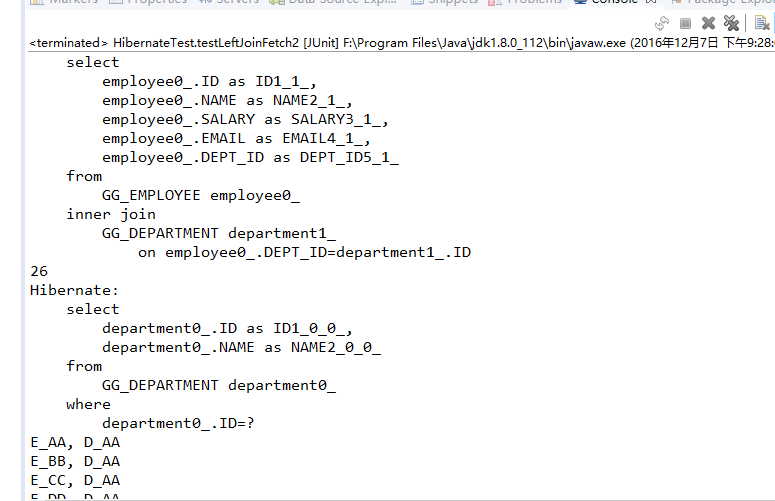
可以根据配置文件来决定Employee集合的检索策略。默认情况下是lazy=true,所以当不使用Employee集合时是不会初始化Employee集合的。但是实际上,当查询Department时,Employee集合已经被查出来了,但是没有被初始化,非要等到使用Employee集合的时候再重新去查一遍。所以通常情况下,如果需要使用到表的左外连接,建议使用迫切的左外连接,因为反正查department的时候都要把employee集合都查出来,不如直接一次初始化完毕。
可以看到,在查询department后已经将employee都查出来了,但是没有初始化employee集合。
下面的程序演示了使用SELECT DISTINCT关键字去重。但是,每当使用到employee集合,还要重新select一遍。

HQL(迫切)内连接
迫切内连接:
HQL使用INNER JOIN FETCH关键字表示迫切内连接,也可以省略INNER关键字。
list()方法返回的集合中存放Department对象的引用,每个Department对象的Employee集合都被初始化,存放所有关联的Employee对象。
如果希望list()方法返回的集合仅包含Department对象,可以在HQL查询语句中使用SELECT关键字。
内连接:
INNER JOIN关键字表示内连接,也可以省略INNER关键字。
list()方法返回的集合中存放的每个元素对应查询结果的一条记录,每个元素都是对象数组类型。
(迫切)内连接和(迫切)左外连接的区别仅在于,(迫切)内连接不会返回从表中没有信息与主表对应的记录。例如,在上面的例子中,有的部门员工数为0,即该部门不存在记录department.id=employee.dept_id,但是(迫切)左外连接仍然会返回该记录,但是(迫切)内连接则不会。如下:
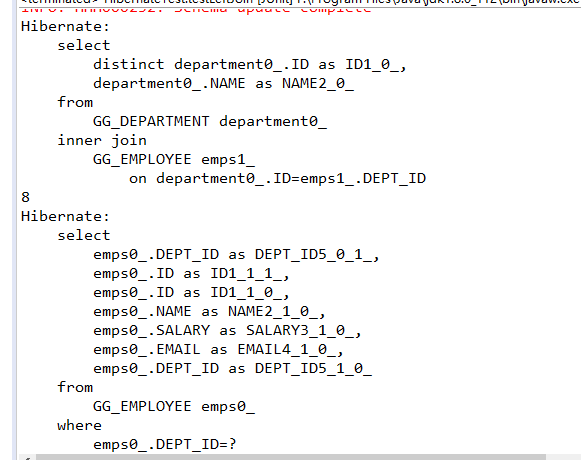
打印的depts.size()不再是上面的10,而是8,因为有6号部门和10号部门没有员工:
如果用SELECT来查询employee,道理也和上面讲述的时一样的,加FETCH会立即初始化department,不加FETCH则会等到使用department时才分别初始化对应的department。