mybatis一级缓存
mybatis一级缓存是SqlSession级别的缓存。
一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。
mybatis默认开启一级缓存。
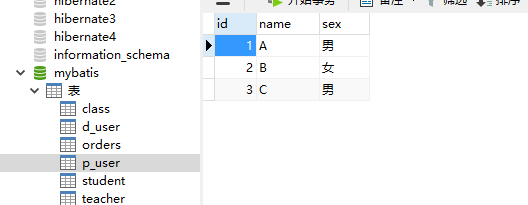
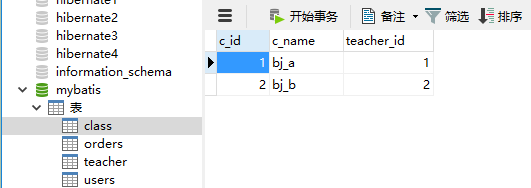
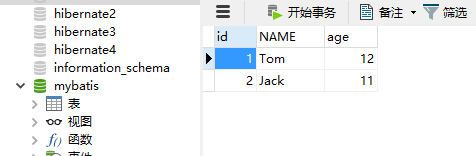
下面测试一级缓存,首先创建数据库表c_user并插入两条数据:
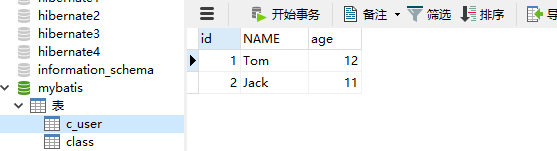
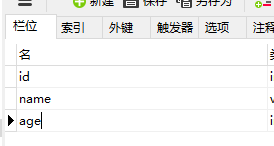
创建实体类CUser:
编写配置文件userMapper.xml:
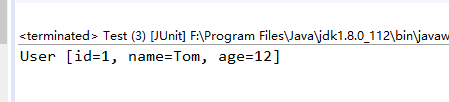
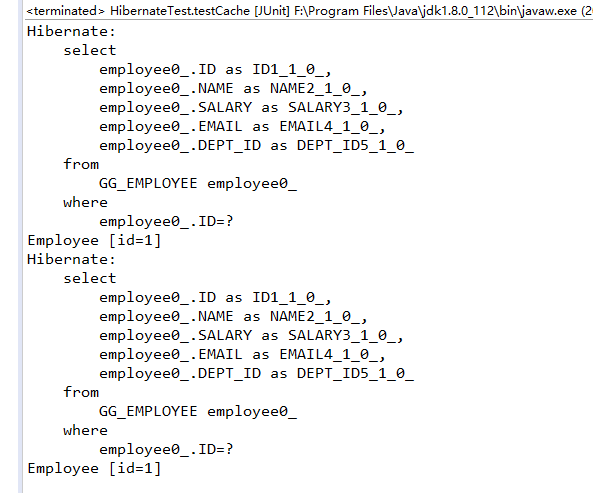
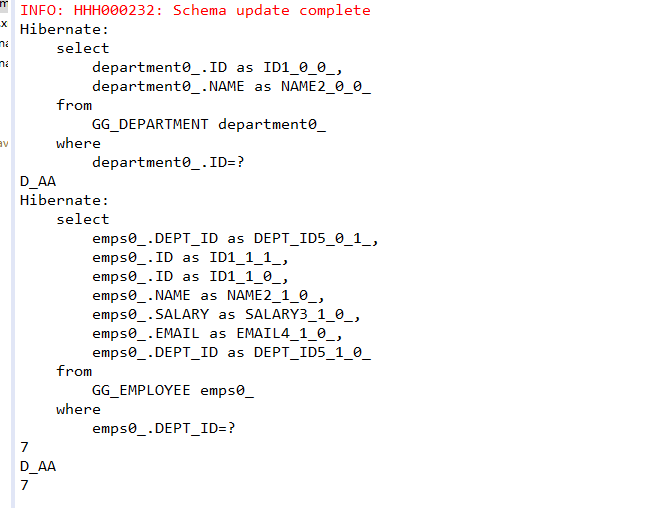
首先测试一级缓存的作用:
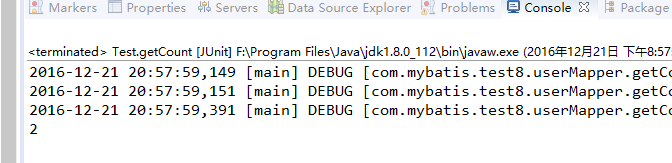
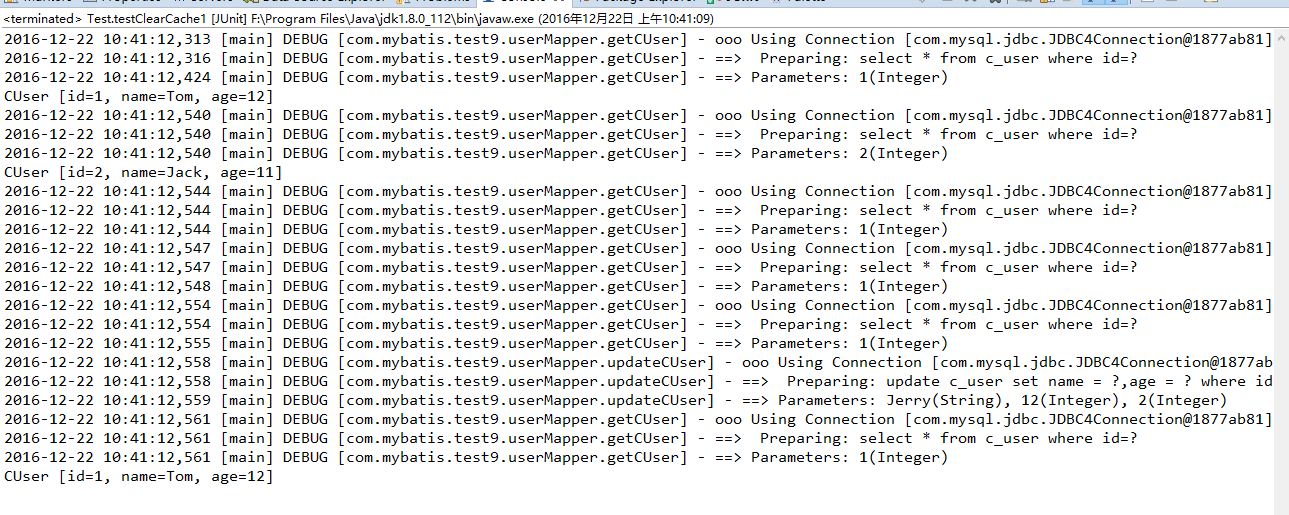
运行结果:

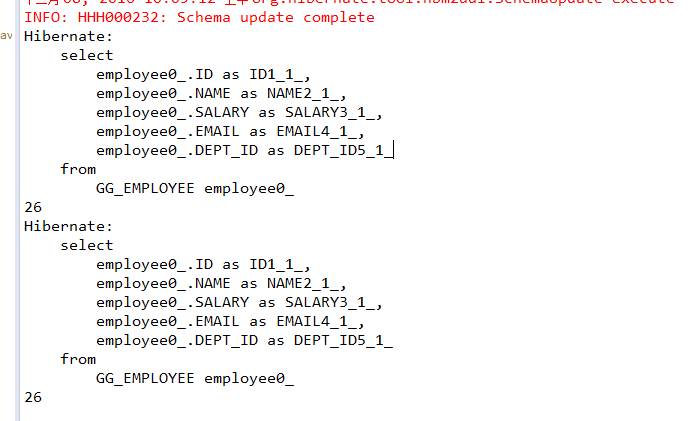
从运行结果中发现,虽然执行了两次selectOne函数,但是只执行了一条SELECT语句。这是由于两次查找的条件相同,即都是查询id为1的记录,所以缓存起了作用,第二次执行selectOne方法并没有重新去数据库查询记录。
那么,哪些情况下会重新去数据库执行查询操作呢?有下面几种情况:
运行结果:
mybatis二级缓存
mybatis二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql操作且向sql中传递参数也相同,即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。
在mybatis的配置文件中,二级缓存的总开关默认已经开启,但是对应的映射文件中没有配置开启二级缓存,所以需要在具体的mapper.xml中开启二级缓存。
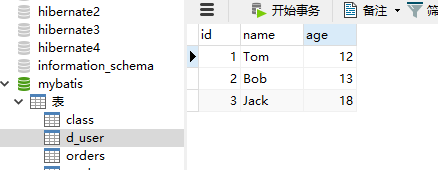
下面测试mybatis二级缓存,首先需要在对应的映射文件中开启二级缓存:
而且需要是被缓存的实体类实现Serializable接口:
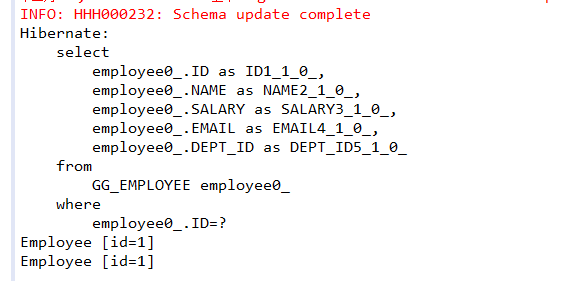
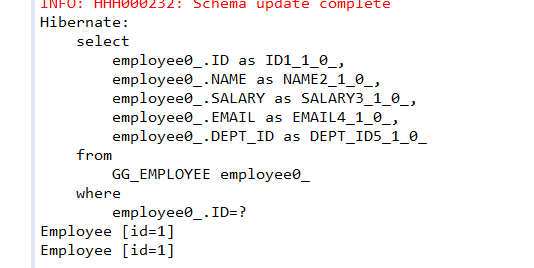
编写测试类测试二级缓存:
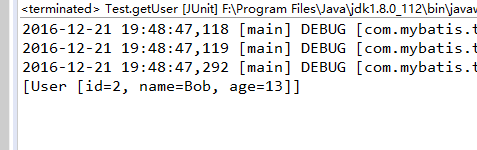
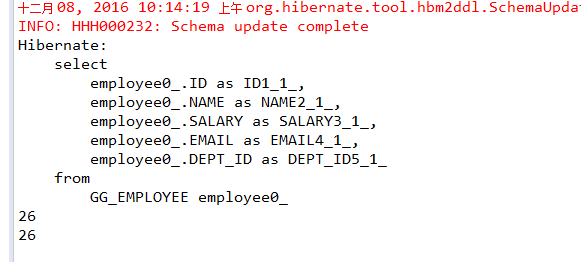
运行结果:
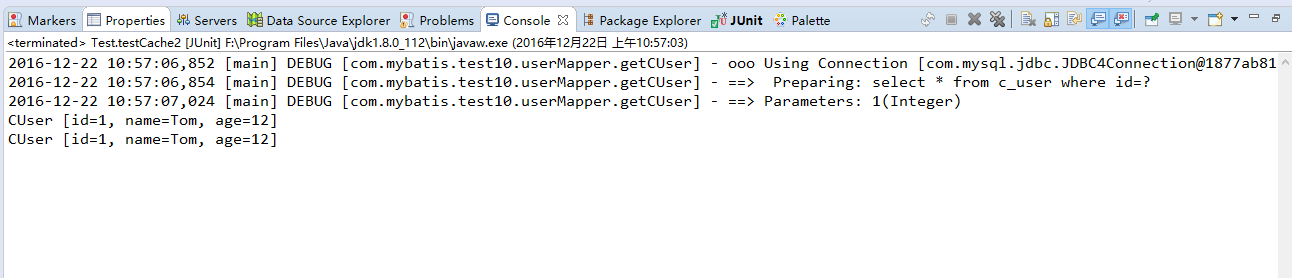
可以看到,虽然是通过两个不同的SqlSession查询记录,但是只执行了一次SELECT语句,这正是mybatis二级缓存的作用。
注意点:
- 需要在对应的映射文件中配置开启二级缓存。
- 被缓存的实体类需要实现Serializable接口。
- SqlSession必须执行commit或者close方法后,其中的数据才会被写入到二级缓存。
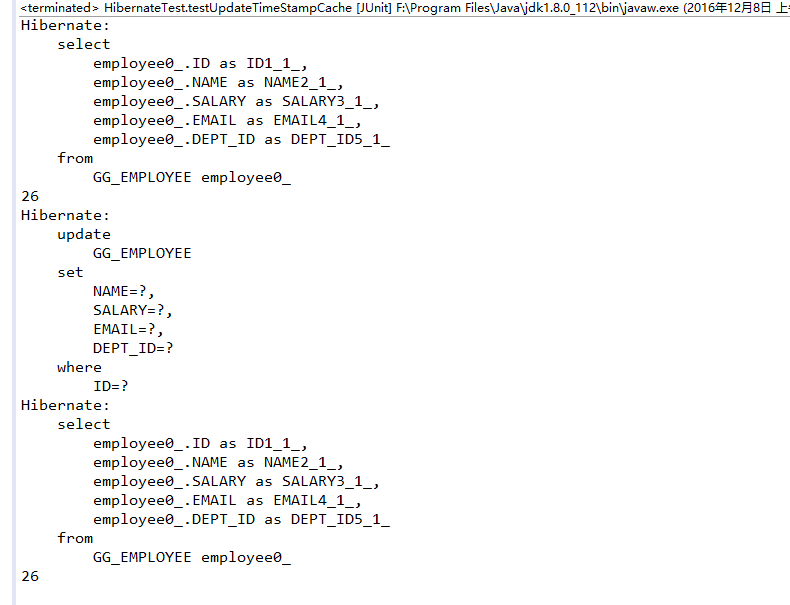
- 当执行了增删改操作后,会刷新二级缓存:123456789101112131415161718192021222324252627.junit.Testpublic void testClearCache2() {String resource = "conf.xml";InputStream is = this.getClass().getClassLoader().getResourceAsStream(resource);SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);//获取两个不同的SqlSessionSqlSession session1 = sessionFactory.openSession();SqlSession session2 = sessionFactory.openSession();String statement1 = "com.mybatis.test10.userMapper"+".getCUser";String statement2 = "com.mybatis.test10.userMapper"+".updateCUser";CUser user1 = session1.selectOne(statement1, 1);//当执行了增删改操作后,会刷新二级缓存CUser newUser = new CUser(2, "Bob", 14);session1.update(statement2,newUser);session1.commit();CUser user2 = session2.selectOne(statement1, 1);System.out.println(user1);System.out.println(user2);}
运行结果如下: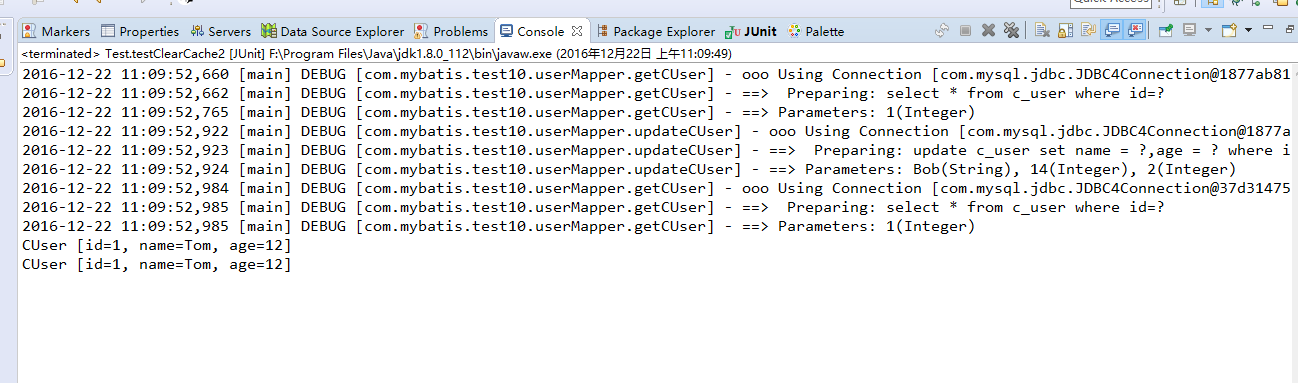
在映射文件中配置开启二级缓存时,cache节点还可以配置如下属性: